




Table of contents
Introduction
In the following series, we’re going to explore some of the intermediate to advanced techniques available to us when using an SQL or relational database. We’ll assume you have some basic experience with the Structured Query Language (SQL). As a baseline, you should have some basic experience with SQL and be aware of the SELECT and JOIN statements to follow along with this article. The examples that follow use syntax suited for PostgreSQL or MySQL databases.
When you have your data distributed among multiple tables, it makes sense that sometimes you need to combine or aggregate multiple tables together to extract meaning from your data. There are multiple ways this can be done. One way would be to JOIN tables together and filter using a WHERE clause. But, there are times when a simple JOIN isn’t the superpower you were looking for. When JOINing tables together, you’re only able to view multiple tables as one, but this may not be the most effective way to get information from your data. This just becomes a view of the data that you already have, which doesn’t help when you’re trying to learn from your data in a non-trivial way as part of data analysis or business intelligence. You can think of data without meaning as just measurements.
Example scenario
Let’s set the stage for the following examples by providing an Entity Relationship Diagram (ERD) of the database we’ll be using.
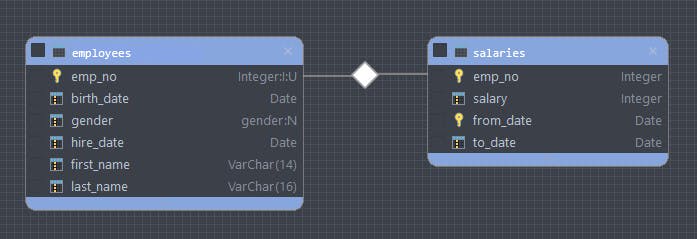
Here, we have two tables in our database. The first is the employees table and the second is the salaries table with the various fields listed for each table. As you can see, the two tables are related to each other with the emp_no as the Primary Key. In Part 1 of this series, we will only concern ourselves with the employees table. We’ll now proceed to the non-trivial question we want to answer.
The question we want to answer is: How many employees have an age greater than the average age of all employees?
We’ll try to answer this question with a few different solutions. The very first naive solution may involve a simple SELECT query as such:
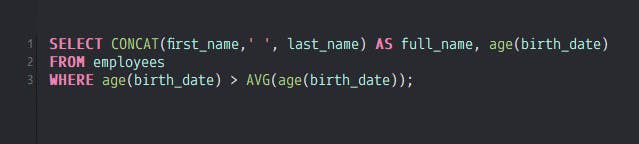
This statement will not work as the SQL engine will not allow you to use aggregate functions in a WHERE clause because the WHERE clause is used to filter data before aggregation. Ok, so we’ll just put the aggregate function into a HAVING clause instead since the HAVING clause allows for aggregation. That’s the difference between the WHERE and the HAVING clauses. So, our next naive solution might be this:
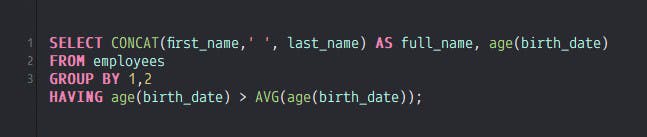
Things get a little more interesting here. First, let me explain why there’s a GROUP BY clause in this statement as it’s very important to understand. When you use an aggregate function like AVG, any unaggregated fields in the SELECT clause must either be in the GROUP BY clause, or you have to use an aggregate function for each unaggregated field in the SELECT clause, or you can remove the unaggregated fields from the SELECT clause entirely. However, if we remove the name and age in our case, we won’t know who the employees are that have an age greater than the average age of all employees. You might be wondering why aggregation creates this problem for us. When you aggregate on a column, it means we are taking all the values of that column and summarizing it into a single value; the average of all ages of all employees in this case. So, SQL doesn’t know how to relate a single value result with multiple rows, unless we amend the SQL statement. There are other ways around this with a WINDOW function, but that’s a topic for another blog post. We also don’t want to aggregate on the name or age because we want to know each employee that has an age greater than the average age. So, we’re left with using a GROUP BY to prevent an error. Now that we’ve plugged in the GROUP BY, the above SQL statement is valid, but you won’t get any results! Any ideas why? Well, when you have an employees table with rows of name, birth date, etc, your table will contain unique rows. It doesn’t make sense to have duplicate entries in an employees table, since, as an individual, we only have one birth date or age. Keep in mind that this table has all unique rows, and none of the fields in our table can be logically aggregated and give us the answer to our original question. So, when you GROUP BY name and age in a table with all unique rows, there’s nothing to group! So, this SQL statement gives you an empty result–not the solution we were looking for!
Subqueries to the rescue
So, finally, we’ll attempt to answer our question with the use of Subqueries and the following SQL query:
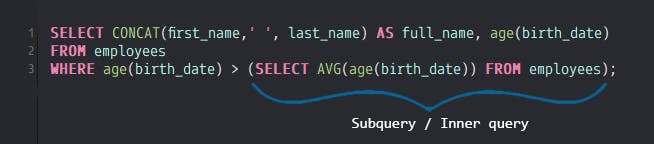
Here, we have an SQL statement with the subquery shown with a blue bracket. You will notice how the subquery, also known as an inner query, is within the full query, which is also known as an outer query. This is why it has the name subquery as it’s a query within another query. Two things to consider when using subqueries are the placement of the subquery within the outer query and whether the subquery needs a dependency on the outer query as a correlated subquery, or as a simple subquery with no dependencies. Two factors dictate the placement of the subquery. The first is the problem you’re trying to solve and the other is the readability of the query. With regards to placement, there are four types of subqueries based on the placement within the outer query: WITH statement subqueries which are also called a Common Table Expression (CTE), nested or WHERE clause subqueries, inline subqueries found within the FROM clause which take the place of a table name and must be aliased, and scalar subqueries within the SELECT clause of the outer query where we select only one column or expression and return a single row. In our example SQL query above, you’ll notice we used a nested subquery as a simple subquery with no dependencies on the outer query.
All subqueries can stand alone as a valid SQL statement and they must be placed inside parenthesis. You can remove the outer query and just run the subquery (without parenthesis) and you’ll get the average age of all employees, in the case of our example SQL query. I would recommend this as the starting point when you think a subquery will be required to answer a question. Start with the subquery statement and make sure you get the correct results as part of the final solution. We know we have to calculate the average age. Now that we have the average age, we can use this result in a WHERE clause and get the name and age of all employees from the outer query that satisfies the WHERE clause. In this situation, you don’t need to use a GROUP BY or aggregate the unaggregated fields in the SELECT clause of the outer query because the AVG function is not part of the outer query. You also don’t need a HAVING clause for the same reason–there is no aggregate function in the outer query. The WHERE clause will only see the result of the subquery and SQL will not complain.
Understanding when a subquery might be of use and where best to place the subquery takes practice, as it seems foreign at first. Although the question we solved in this post was fairly straightforward, subqueries are quite powerful as you can use multiple subqueries in a single SQL statement, use them in conjunction with JOINing tables, or introduce a subquery using another type of placement. Even the nested query we have shown can be part of a complex query based on the problem at hand. Part 2 of this series will dive into some of the other subquery placement types. Until then, I hope this helped or put light on the irreplaceable power of SQL.